关于中文字符编码的二三事
从学习编程以来,基本都一直避免着用到中文。因为中文容易乱码嘛,英文用起来没那么多事。但一直没有深究其中的原因。前段时间做信息安全的实验,各种加密解密。然而助教提了一个要求:要能够处理中文。得,不能再当鸵鸟了,只得好好叨唠叨唠处理中文的问题。其实这玩意,会者不难难者不会。要深究一番也还是有点深度,这里就简单介绍下。
什么是编码?
简单来说,编码对字符来说就像是身份证一样,计算机通过一个编号来唯一确定一种字符。你在敲代码,或者阅读文本时,所看到的字符,其实计算机是不认的。计算机中存储的是其对应的编码,要用的时候先查询这个编码对应的字符,再将字符呈现给你看。
为什么英文不用考虑编码问题?
首先,为什么我们在使用英文时从来没有考虑过编码问题?其实英文字母是有编码的,就是c里面的‘a’=97这样,其中的97就是它的编号。这套编码我们称之为ASCII码,只有0-127。别的编码方式,基本都是兼容ASCII码的,或者说是在ASCII上进行扩展,添加新的字符以及对应的编码。所以,不管你这台设备,或者说这个文件,这个终端用的是什么编码,使用ASCII码的英文一般都能够正常显示,所以不用考虑编码问题。
为什么有时中文会乱码?
上文提到,编码是计算机将编号和字符唯一对应的方式。也就是说,同样的一个编号,在不同编码方式下可能会是完全不同的两个字符。这就是为什么我们有时会遇到中文乱码了。举个很常见的例子,你在VScode写个个小程序,输出中文,F5,一切正常。
#include <bits/stdc++.h>
using namespace std;
signed main(void)
{
cout << "中文" << endl;
system("pause");
return 0;
}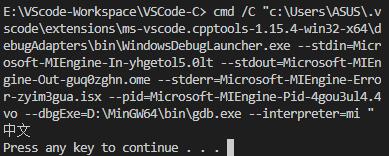
但直接运行编译生成的可执行文件就会乱码:
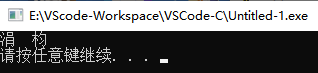
原因就是我们上面讲的,双方使用的编码不一样。我们通过chcp命令来查看两个终端分别用到什么编码:

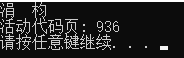
这里输出的是代码页(Code Page),这里我们不做展开。只要知道936对应GBK编码,而65001对应UTF-8编码就行。双方使用的编码不一样,结果也就不一样。
那为什么UTF-8编码的输出才是正确的呢?也许你没有注意到,在使用VScode编辑器时,右下角会有个小小的UTF-8字样:

这是说我们正在以UTF-8编码浏览文件,同样也会以这个编码保存文件。点击这个按钮你还可以切换用其他编码打开或保存文件。
那么原因找到了,我们使用UTF-8的编码保存了文件。编译器编译生成exe文件,里面的“中文”字符串也是UTF-8编码的。而外部终端使用GBK编码打开,于是乱码。
如何解决乱码问题
要解决这个问题,就要让文件和终端的编码一致。我们可以选择用GBK编码保存文件,或者设置终端编码为UTF-8来解决问题。
设置终端编码方式为:SetConsoleOutputCP(65001);(需要windows.h),或者system("chcp 65001");(不需要windows.h)。
关于Qt的中文编码
因为最近Qt用的比较多,就在这里稍微提一下。我是先写好c程序,再用Qt做图形化界面,中途需要在QString和std::string以及char*之间转换。如果转换不当就很容易出问题。
Qt的QString用的是unicode编码,在使用.toStdString()转化成std::string后就变成了UTF-8编码。Qt转换成char*虽然有多种方式,但我还是推荐先转成std::string再用.c_str()转成char*,这样路径明晰,兼容性也会好些。这时的char*也是UTF-8编码。
需要转回Qt时,std::string用QString::fromStdString(),char*用QString::fromUtf8()就行。